


We Are in the Productivity Trough and This Is Historically Normal.
Note: This was also published on Brinton Bio’s Working Note Substack page.
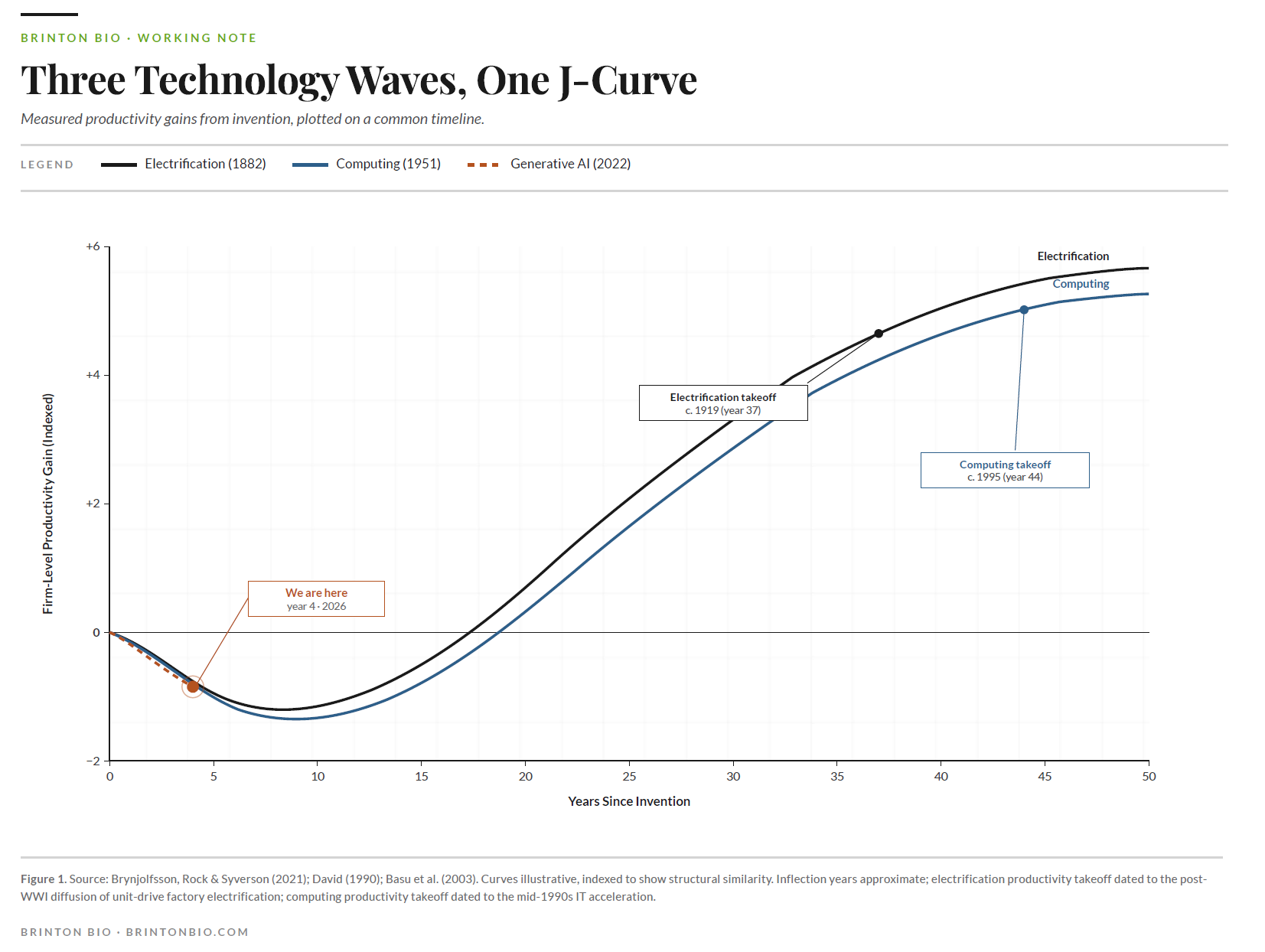
In 1919, the electric motor finally crossed fifty percent of American factory horsepower; thirty-seven years after Edison's Pearl Street station lit lower Manhattan. For most of those thirty-seven years, electricity was a curiosity with a weak business case. Factories that installed it tended to drop a motor onto the existing line-shaft system and tinker in an attempt to find profit. The ones that eventually got the gains rebuilt the factory around the motor, with unit drive, rearranged workflow, new management structures, and different training. That took decades because it required admitting the old factory was the problem.
Computing ran the same pattern. IBM shipped the System/360 in 1964 and the PC landed in 1981. For twenty years after that, CFOs stared at enormous IT budgets and couldn't find the return in the numbers. Robert Solow made the joke everyone still quotes. You could see the computer age everywhere but in the productivity statistics. The numbers finally showed up in the late 1990s. Economists called it a miracle, but it was the cumulative harvest of fifteen years of companies rebuilding themselves around the technology, mostly badly, with the survivors compounding.
The internet looked faster than this. Measured lag from commercialization to firm-level gains was around five years. Except the economists who studied it, Basu, Fernald, Oulton, and Srinivasan in 2003, traced the 1990s acceleration back to ICT capital that firms had been accumulating since the mid-1980s. The internet harvested ten years of prior work in five rather than produce a ten-year gain in five years.
This is the finding that should bother anyone betting a trillion dollars on generative AI over the next eighteen months or making AI the centerpiece of their investments today. Every major technology wave has run on roughly the same clock. The apparent acceleration was an accounting artifact. The compression was never real.
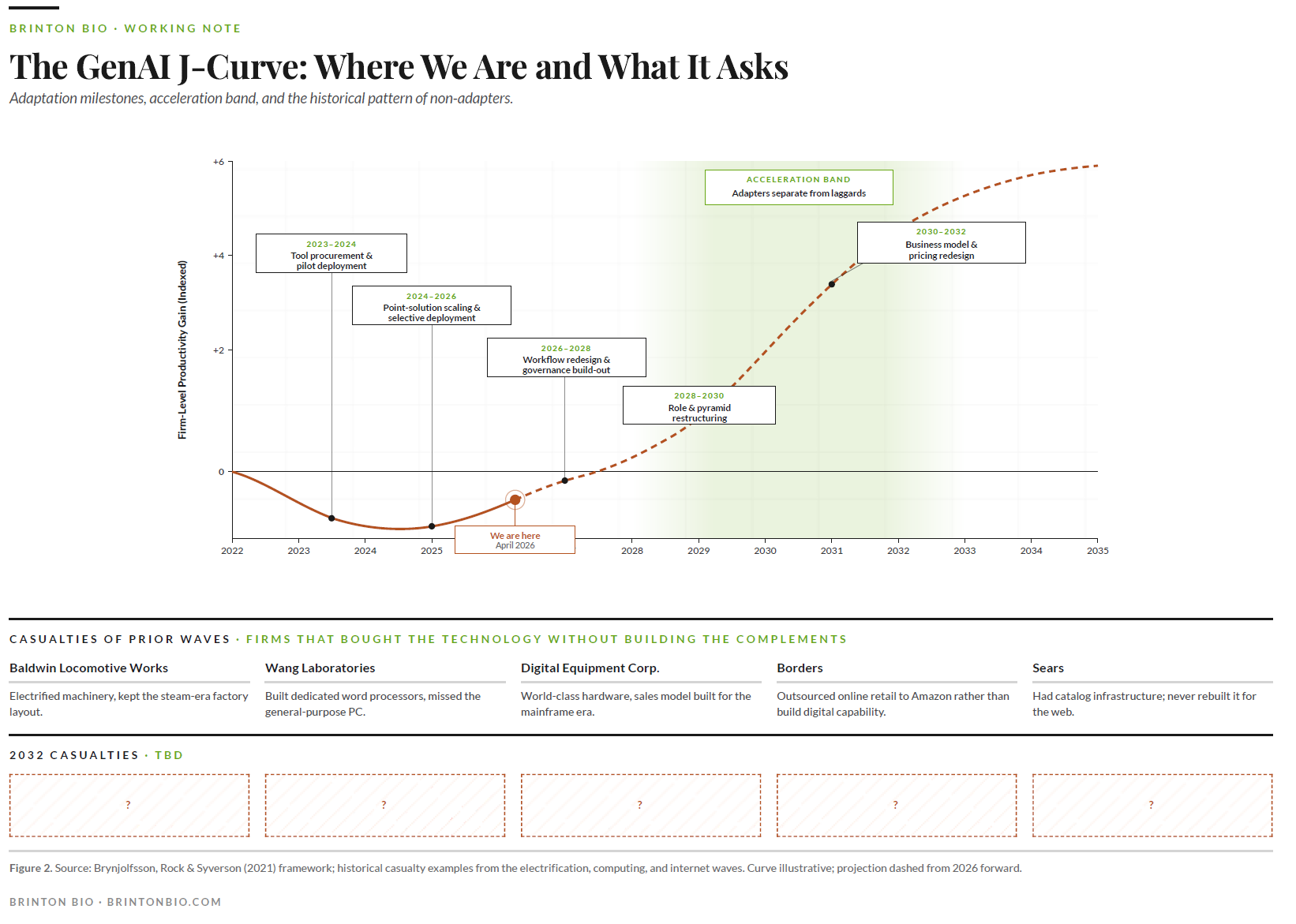
Which brings us to April 2026.
We have robust task-level evidence that generative AI makes individuals faster. Fourteen to fifty-six percent gains across a dozen randomized controlled trials. We have essentially zero firm-level evidence of productivity gains. Goldman Sachs conceded it in January. The Penn Wharton Budget Model attributes one one-hundredth of a percentage point of 2025 TFP growth to AI.
This divergence is exactly what the historical record predicts for year three of a general-purpose technology. The gains are real at the task level, but they have not yet shown up at the firm level because firms haven't done the work yet. The work is the thing, and it has always been the thing.
Brynjolfsson, Rock, and Syverson formalized the pattern as a productivity J-curve. Firms invest heavily in complements that national accounts don't capture: workflow redesign, data infrastructure, training, governance, new roles, new decision rights. Measured productivity falls during the investment phase because the inputs are counted and the outputs aren't yet. Then the curve bends. Firms that built the complements harvest them. Firms that didn't, don't.
The one thing that actually might be different this time.
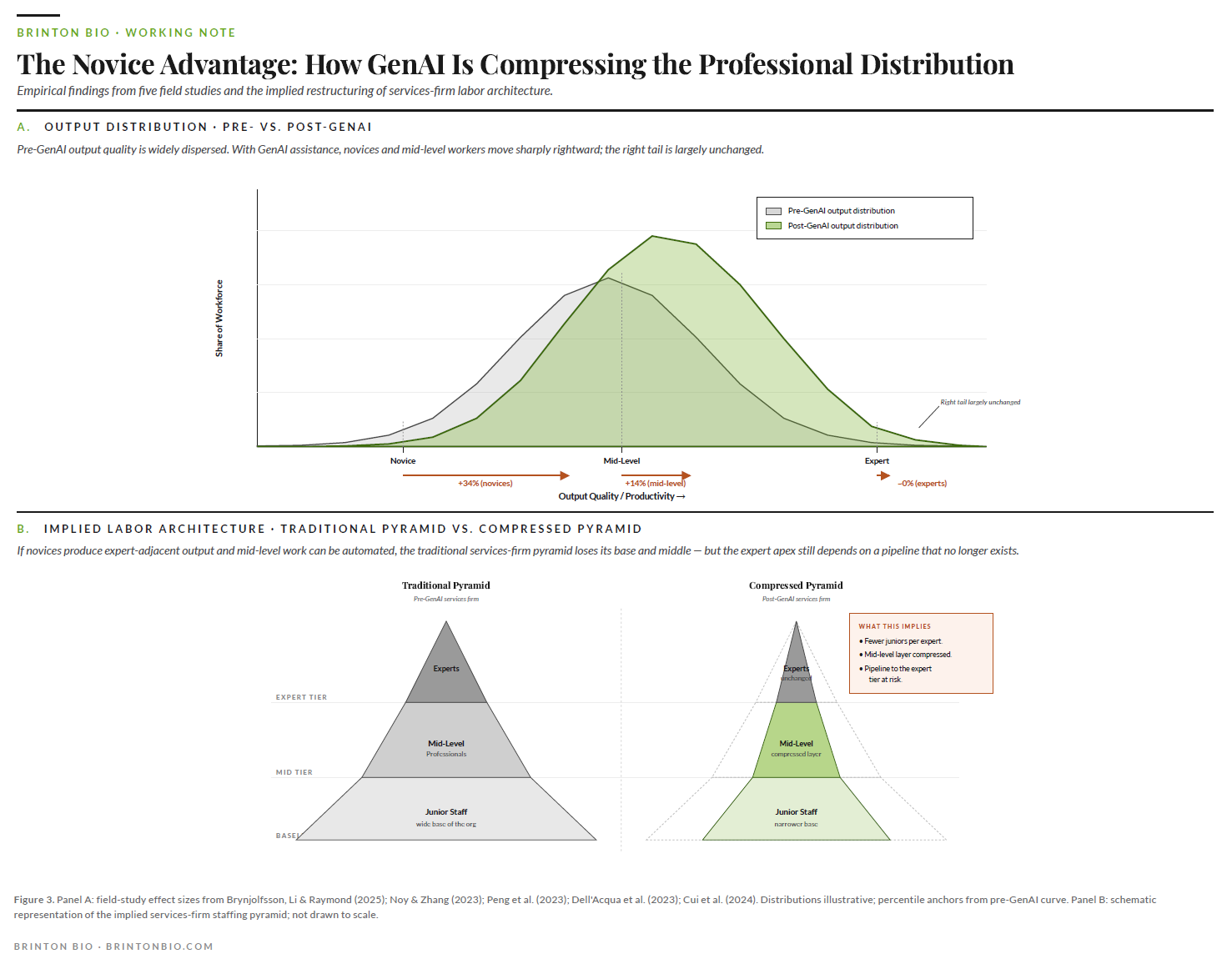
Across many serious field study of generative AI so far, Noy and Zhang, Brynjolfsson-Li-Raymond, Peng, Dell'Acqua, Cui, there is a similar trend (causing panic in many circles). Novices gain more than experts. In the largest customer support study to date, novices improved thirty-four percent and experienced agents improved roughly zero. In coding, consulting deliverables, and professional writing, the bottom half of the distribution closes most of the gap with the top half.
Historically, new technologies widened skill premiums for a decade or more. Electrification favored engineers. Computing favored knowledge workers. This wave appears to be compressing skill premiums from day one. If the pattern holds in firm-level data over the next eighteen months, the labor economics of every services business gets rewritten.
What this feels like for PE operating partners.
The labor arbitrage model inverts. Services portcos have historically made money by having a few expensive experts supervising a lot of cheaper junior staff. The economics worked because expert time was scarce and junior time was plentiful. GenAI changes expert productivity very little. Experts already work near the capability frontier. It changes junior productivity dramatically. A junior analyst with GenAI produces something closer to mid-level output. A mid-level person with GenAI produces something closer to senior output on routine work.
The pyramid gets squeezed. You don't need as many juniors to support each expert, because each junior is doing more. You don't need as many mid-level people to supervise the juniors, because the juniors' work needs less correction. The billable-hours pricing model breaks, because the hours required to produce a deliverable are dropping faster than clients will tolerate price increases.
What this will feel like: revenue per head rises, headcount growth stalls, junior roles get harder to justify, and three years later someone notices there's no pipeline of people who could become experts because nobody was training them. The firms that figure out how to reprice, moving from hourly to outcome-based, from headcount-scaled to capability-scaled, pull away. The firms that don't watch their margins erode while their competitors' expand.
What this feels like for pharma ops leaders.
Different shape, same underlying mechanic. The expert in pharma is valuable because they know what will get past FDA, what will hold up in a Type B meeting, what a reviewer will flag. That kind of tacit judgment is exactly what GenAI currently does worst. So inside pharma, the novice advantage shows up most visibly in work that is high-volume, pattern-based, and quality-bounded: medical writing first drafts, literature review, regulatory document assembly, safety aggregation, protocol templating.
The medical writers, regulatory associates, and clinical ops specialists, the whole layer of well-trained, credentialed professional staff who do the careful structured work pharma runs on, suddenly produce more per person. The expert layer above them is not threatened yet. The layer below them, the traditional entry point into these careers, becomes harder to justify hiring. Same pipeline problem as services, different timeline.
There is a second-order effect specific to regulated industries. When the floor rises, quality variance falls. A pharma ops group whose junior staff produce ninetieth-percentile work instead of fiftieth-percentile work has a different risk profile. Inspection-readiness improves, audit-trail defensibility strengthens, deviation rates drop. That is a CFO-level argument, not a tooling argument.
What the J-curve actually requires.
The firms that will separate from the pack in the early 2030s are the ones using the current trough to rebuild their labor architecture. The complementary capital economists measure is built at the level of governance, workflows, roles, and decision rights. It is invisible, expensive, and hard to commission. It is also the only thing that has ever produced firm-level gains from a general-purpose technology.
The operator question is not whether AI will deliver. It will. The historical schedule is clear. The question is which firms will be running the complementary capital build-out over the next five years and which will still be treating AI as a procurement decision when the data starts to separate them.
The J-curve does not ask nicely. It arrives on its own schedule. The firms that understand what phase they are in are the ones that get to harvest.
If you are a PE operating partner watching your services portcos produce less operating leverage from AI than the investment committee expected, the J-curve explains why. Happy to walk through the pattern across a portfolio.
If you are a pharma ops leader trying to figure out where headcount should go in the 2027 budget while your medical writing and regulatory teams quietly produce more per head, the labor architecture question is the one worth asking. Happy to compare notes.
The specifics of what a rebuilt workflow actually looks like inside a pharma ops group, and how firms solve the expert-pipeline problem the compression creates, are conversations I am having with a small number of operators this quarter. If either question is live for you, reach out.
Andrew Ryscavage runs Brinton Bio, a consulting practice focused on AI adoption and operational transformation in life sciences. His background spans NIH, Monitor Deloitte, and Scimitar, with a decade of operating experience inside life sciences companies.
References
Acemoglu, Daron. "The Simple Macroeconomics of AI." NBER Working Paper 32487, 2024.
Basu, Susanto, John G. Fernald, Nicholas Oulton, and Sylaja Srinivasan. "The Case of the Missing Productivity Growth: Or, Does Information Technology Explain Why Productivity Accelerated in the United States but Not the United Kingdom?" NBER Working Paper 10010, 2003.
Brynjolfsson, Erik, and Lorin M. Hitt. "Computing Productivity: Firm-Level Evidence." Review of Economics and Statistics 85, no. 4 (2003): 793-808.
Brynjolfsson, Erik, Danielle Li, and Lindsey R. Raymond. "Generative AI at Work." Quarterly Journal of Economics 140, no. 2 (2025): 889-942.
Brynjolfsson, Erik, Daniel Rock, and Chad Syverson. "The Productivity J-Curve: How Intangibles Complement General Purpose Technologies." American Economic Journal: Macroeconomics 13, no. 1 (2021): 333-372.
Crafts, Nicholas. "Steam as a General Purpose Technology: A Growth Accounting Perspective." Economic Journal 114, no. 495 (2004): 338-351.
Cui, Zheyuan, Mert Demirer, Sonia Jaffe, Leon Musolff, Sida Peng, and Tobias Salz. "The Effects of Generative AI on High Skilled Work: Evidence from Three Field Experiments with Software Developers." SSRN Working Paper, 2024.
David, Paul A. "The Dynamo and the Computer: An Historical Perspective on the Modern Productivity Paradox." American Economic Review 80, no. 2 (1990): 355-361.
Dell'Acqua, Fabrizio, Edward McFowland III, Ethan Mollick, Hila Lifshitz-Assaf, Katherine Kellogg, Saran Rajendran, Lisa Krayer, François Candelon, and Karim R. Lakhani. "Navigating the Jagged Technological Frontier: Field Experimental Evidence of the Effects of AI on Knowledge Worker Productivity and Quality." Harvard Business School Working Paper 24-013, 2023.
Jorgenson, Dale W. "Information Technology and the U.S. Economy." American Economic Review 91, no. 1 (2001): 1-32.
Noy, Shakked, and Whitney Zhang. "Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence." Science 381, no. 6654 (2023): 187-192.
Oliner, Stephen D., and Daniel E. Sichel. "The Resurgence of Growth in the Late 1990s: Is Information Technology the Story?" Journal of Economic Perspectives 14, no. 4 (2000): 3-22.
Peng, Sida, Eirini Kalliamvakou, Peter Cihon, and Mert Demirer. "The Impact of AI on Developer Productivity: Evidence from GitHub Copilot." arXiv preprint 2302.06590, 2023.